SpaceX Falcon 9 first stage Landing Prediction
TABLE OF CONTENTS
- Skills
- Executive Summary
- Introduction
- Methodology
- Data collection and webscraping
- Data wrangling
- Exploratory data analysis with SQL
- Exploratory data analysis with pandas and matplotlib
- Interactive visual analytics with folium lab
- Machine learning prediction
- Discussion
- Conclusion
Skills
-
DATA COLLECTION AND WEBSCRAPING - beautifulsoup,requests, pandas
-
DATA WRANGLING- missing values, pandas
-
EXPLORATORY DATA ANALYSIS WITH SQL
-
EXPLORATORY DATA ANALYSIS WITH PANDAS AND MATPLOTLIB
-
INTERACTIVE VISUAL ANALYTICS WITH FOLIUM LAB
-
MACHINE LEARNING PREDICTION
EXECUTIVE SUMMARY
- The Falcon 9 rocket launches is estimated to be about 62 million dollars which is cheaper than other providers due to SpaceX ability to reuse the first stage
- Data source is from SpaceX API (get request) and Wikipedia (web scraping)
- EDA was done using SQL , Pandas, Matplotlib, plotly dashboard and Interactive visual Analytics with Folium lab
- Factors associated with success rate of the Falcon 9 rocket launches includes the launch sites, payload mass, orbit type and year of launch
- All classification algorithm used in prediction yielded the same accuracy of 83%.
INTRODUCTION
- The aim of this project is to predict if the Falcon 9 rocket first stage will land successfully
- The Falcon 9 rocket launches is estimated to be about 62 million dollars which is cheaper than other providers due to SpaceX ability to reuse the first stage
- We will determine if the first stage will land, and this will help to determine the cost of the launches.
- This information can be beneficial if another company intend to bid against SpaceX for a rocket launch.
METHODOLOGY
- Data source id from SpaceX API (get request) and Wikipedia (web scraping)
- Data cleaning to remove missing values
- EDA was done using SQL , Pandas, Matplotlib and Plotly Dashboard
- Interactive visual Analytics is done with Folium lab
- Analysis was done using machine learning classification methods - – Logistics Regression – Decision tree – K nearest neighbors – Support vector machines
1. DATA COLLECTION AND WEBSCRAPING
Web scraping to collect Falcon 9 historical launch records from a Wikipedia page titled ‘List of Falcon 9 and Falcon Heavy launches’
https://en.wikipedia.org/wiki/List_of_Falcon_9_and_Falcon_Heavy_launches?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork26802033-2021-01-01
!pip3 install beautifulsoup4
!pip3 install requests
import sys
import requests
from bs4 import BeautifulSoup
import re
import unicodedata
import pandas as pd
#Helper functions for you to process web scraped HTML table
def date_time(table_cells):
"""
This function returns the data and time from the HTML table cell
Input: the element of a table data cell extracts extra row
"""
return [data_time.strip() for data_time in list(table_cells.strings)][0:2]
def booster_version(table_cells):
"""
This function returns the booster version from the HTML table cell
Input: the element of a table data cell extracts extra row
"""
out=''.join([booster_version for i,booster_version in enumerate( table_cells.strings) if i%2==0][0:-1])
return out
def landing_status(table_cells):
"""
This function returns the landing status from the HTML table cell
Input: the element of a table data cell extracts extra row
"""
out=[i for i in table_cells.strings][0]
return out
def get_mass(table_cells):
mass=unicodedata.normalize("NFKD", table_cells.text).strip()
if mass:
mass.find("kg")
new_mass=mass[0:mass.find("kg")+2]
else:
new_mass=0
return new_mass
def extract_column_from_header(row):
"""
This function returns the landing status from the HTML table cell
Input: the element of a table data cell extracts extra row
"""
if (row.br):
row.br.extract()
if row.a:
row.a.extract()
if row.sup:
row.sup.extract()
colunm_name = ' '.join(row.contents)
# Filter the digit and empty names
if not(colunm_name.strip().isdigit()):
colunm_name = colunm_name.strip()
return colunm_name
url= "https://en.wikipedia.org/wiki/List_of_Falcon_9_and_Falcon_Heavy_launches?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDS0321ENSkillsNetwork26802033-2021-01-01"
Requesting the Falcon9 Launch Wiki page from its URL
#Using the HTTP GET method to request the Falcon9 Launch HTML page, as an HTTP response
data = requests.get(url).text
#Create a BeautifulSoup object from the HTML response
soup = BeautifulSoup(data, 'html5lib')
#Print the page title to verify if the BeautifulSoup object was created properly
tag_object=soup.title
print("tag object:",tag_object)
Extract all column/variable names from the HTML table header
html_tables= soup.find_all('table')
# Let's print the third table and check its content
first_launch_table = html_tables[2]
print(first_launch_table)
#Iterate through the <th> elements and apply the provided extract_column_from_header() to extract column name one by one
column_names = []
# Apply find_all() function with `th` element on first_launch_table
col=first_launch_table.find_all('th')
# Iterate each th element and apply the provided extract_column_from_header() to get a column name
for row in col:
name=extract_column_from_header(row)
# Append the Non-empty column name (`if name is not None and len(name) > 0`) into a list called column_names
if name is not None and len(name)>0:
column_names.append(name)
print(column_names)
Create a data frame by parsing the launch HTML tables
#create an empty dictionary with keys from the extracted column names in the previous task. Later, this dictionary will be converted into a Pandas dataframe
launch_dict= dict.fromkeys(column_names)
# Remove an irrelvant column
del launch_dict['Date and time ( )']
# Let's initial the launch_dict with each value to be an empty list
launch_dict['Flight No.'] = []
launch_dict['Launch site'] = []
launch_dict['Payload'] = []
launch_dict['Payload mass'] = []
launch_dict['Orbit'] = []
launch_dict['Customer'] = []
launch_dict['Launch outcome'] = []
# Added some new columns
launch_dict['Version Booster']=[]
launch_dict['Booster landing']=[]
launch_dict['Date']=[]
launch_dict['Time']=[]
extracted_row = 0
#Extract each table
for table_number,table in enumerate(soup.find_all('table',"wikitable plainrowheaders collapsible")):
# get table row
for rows in table.find_all("tr"):
#check to see if first table heading is as number corresponding to launch a number
if rows.th:
if rows.th.string:
flight_number=rows.th.string.strip()
flag=flight_number.isdigit()
else:
flag=False
#get table element
row=rows.find_all('td')
#if it is number save cells in a dictonary
if flag:
extracted_row += 1
# Flight Number value
# Append the flight_number into launch_dict with key `Flight No.`
#print(flight_number)
datatimelist=date_time(row[0])
# Date value
# Append the date into launch_dict with key `Date`
date = datatimelist[0].strip(',')
#print(date)
# Time value
# Append the time into launch_dict with key `Time`
time = datatimelist[1]
#print(time)
# Booster version
# Append the bv into launch_dict with key `Version Booster`
bv=booster_version(row[1])
if not(bv):
bv=row[1].a.string
print(bv)
# Launch Site
# Append the bv into launch_dict with key `Launch Site`
launch_site = row[2].a.string
#print(launch_site)
# Payload
# Append the payload into launch_dict with key `Payload`
payload = row[3].a.string
#print(payload)
# Payload Mass
# Append the payload_mass into launch_dict with key `Payload mass`
payload_mass = get_mass(row[4])
#print(payload)
# Orbit
# Append the orbit into launch_dict with key `Orbit`
orbit = row[5].a.string
#print(orbit)
# Customer
# Append the customer into launch_dict with key `Customer`
#customer = row[6].a.string
#print(customer)
# Launch outcome
# Append the launch_outcome into launch_dict with key `Launch outcome`
launch_outcome = list(row[7].strings)[0]
#print(launch_outcome)
# Booster landing
# Append the launch_outcome into launch_dict with key `Booster landing`
booster_landing = landing_status(row[8])
#print(booster_landing)
df=pd.DataFrame(launch_dict)
df
#export it to a CSV
df.to_csv('spacex_web_scraped.csv', index=False)
2. DATA WRANGLING
import pandas as pd
import numpy as np
#Load Space X dataset
df=pd.read_csv("https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DS0321EN-SkillsNetwork/datasets/dataset_part_1.csv")
df.head(10)
#mising values
df.isnull().sum()/df.count()*100
#Identify which columns are numerical and categorical:
df.dtypes
Number of launches on each site
df['LaunchSite'].value_counts()
Number and occurrence of each orbit
df['Orbit'].value_counts()
Number and occurence of mission outcome per orbit type
landing_outcomes=df['Outcome'].value_counts()
landing_outcomes
True Ocean means the mission outcome was successfully landed to a specific region of the ocean while False Ocean means the mission outcome was unsuccessfully landed to a specific region of the ocean. True RTLS means the mission outcome was successfully landed to a ground pad False RTLS means the mission outcome was unsuccessfully landed to a ground pad.True ASDS means the mission outcome was successfully landed to a drone ship False ASDS means the mission outcome was unsuccessfully landed to a drone ship. None ASDS and None None these represent a failure to land.
for i,outcome in enumerate(landing_outcomes.keys()):
print(i,outcome)
bad_outcomes=set(landing_outcomes.keys()[[1,3,5,6,7]])
bad_outcomes
Create a landing outcome label from Outcome column
# landing_class = 0 if bad_outcome
# landing_class = 1 otherwise
landing_class=[]
for i in df['Outcome']:
if i in bad_outcomes:
landing_class.append(0)
else:
landing_class.append(1)
df['Class']=landing_class
df[['Class']].head(8)
df.head(5)
#Success rate
df["Class"].mean()
df.to_csv("dataset_part_2.csv", index=False)
3. EXPLORATORY DATA ANALYSIS WITH SQL
!pip3 install ipython-sql
!pip3 install sqlalchemy==1.3.9
!pip3 install ibm_db_sa
%load_ext sql
%sql ibm_db_sa://fml32860:TmIzXipqvn7JQN8O@fbd88901-ebdb-4a4f-a32e-9822b9fb237b.c1ogj3sd0tgtu0lqde00.databases.appdomain.cloud:32731/bludb?security=SSL
Names of the unique launch sites in the space mission
%sql select distinct(LAUNCH_SITE)from SPACEXTBL;
5 records where launch sites begin with the string ‘CCA’
%sql select * from SPACEXTBL where LAUNCH_SITE like 'CCA%' limit 5;
Total payload mass carried by boosters launched by NASA (CRS)
%sql select sum (PAYLOAD_MASS__KG_) from SPACEXTBL where customer = 'NASA (CRS)';
Average payload mass carried by booster version F9 v1.1
%sql select avg (PAYLOAD_MASS__KG_) from SPACEXTBL where BOOSTER_VERSION='F9 v1.1';
List the date when the first successful landing outcome in ground pad was acheived.
%sql select min(DATE) from SPACEXTBL where LANDING__OUTCOME = 'Success (ground pad)';
Names of the boosters which have success in drone ship and have payload mass greater than 4000 but less than 6000
%sql select BOOSTER_VERSION, LANDING__OUTCOME, PAYLOAD_MASS__KG_ from SPACEXTBL where LANDING__OUTCOME='Success (drone ship)' and PAYLOAD_MASS__KG_ BETWEEN 4000 and 6000;
The total number of successful and failure mission outcomes
%sql select MISSION_OUTCOME, count(MISSION_OUTCOME)from SPACEXTBL Group by MISSION_OUTCOME;
The names of the booster_versions which have carried the maximum payload mass. Use a subquery
%sql select BOOSTER_VERSION, PAYLOAD_MASS__KG_ from SPACEXTBL where BOOSTER_VERSION in \
(select BOOSTER_VERSION from SPACEXTBL order by PAYLOAD_MASS__KG_ desc limit 1);
The failed landing_outcomes in drone ship, their booster versions, and launch site names for in year 2015
%sql select BOOSTER_VERSION,DATE, LANDING__OUTCOME, LAUNCH_SITE from SPACEXTBL where LANDING__OUTCOME like '%drone%'and\
DATE like '2015%' ;
Rank the count of landing outcomes (such as Failure (drone ship) or Success (ground pad)) between the date 2010-06-04 and 2017-03-20, in descending order
%sql SELECT LANDING__OUTCOME FROM SPACEXTBL WHERE DATE BETWEEN '2010-06-04' AND '2017-03-20' ORDER BY DATE DESC GROUP BY count(LANDING__OUTCOME);
4. EXPLORATORY DATA ANALYSIS WITH PANDAS AND MATPLOTLIB
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df.head(5)
FlightNumber vs. PayloadMass
sns.catplot(y="PayloadMass", x="FlightNumber", hue="Class", data=df, aspect = 5)
plt.xlabel("Flight Number",fontsize=20)
plt.ylabel("Pay load Mass (kg)",fontsize=20)
plt.show()

Relationship between Flight Number and Launch Site
sns.catplot(y="LaunchSite", x="FlightNumber", hue="Class", data=df, aspect = 5)
plt.xlabel("Flight Number",fontsize=20)
plt.ylabel("Launch Site",fontsize=20)
plt.show()

Relationship between Payload and Launch Site
sns.catplot(y="LaunchSite", x="PayloadMass", hue="Class", data=df, aspect = 5)
plt.xlabel("Payload Mass (KG)",fontsize=20)
plt.ylabel("Launch Site",fontsize=20)
plt.show()

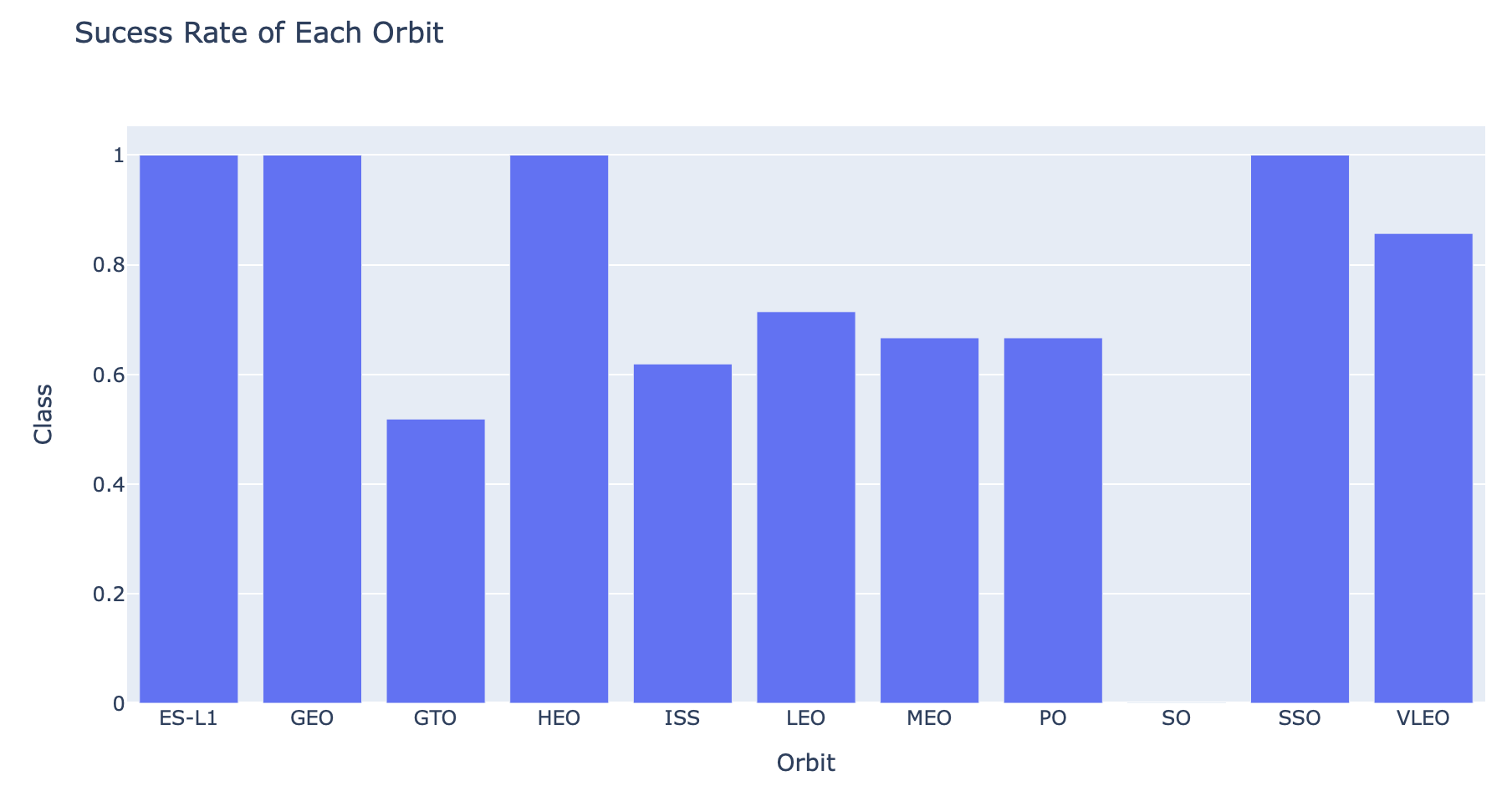
Relationship between success rate of each orbit type
import plotly.express as px
barchart= df.groupby(['Orbit'])['Class'].mean().reset_index()
fig = px.bar(barchart, x="Orbit", y="Class", title='Sucess Rate of Each Orbit')
fig.show()
Relationship between FlightNumber and Orbit type
sns.catplot(y="Orbit", x="FlightNumber", hue="Class", data=df, aspect = 5)
plt.xlabel("Flight Number",fontsize=20)
plt.ylabel("Orbit",fontsize=20)
plt.show()

Relationship between Payload and Orbit type
sns.catplot(y="Orbit", x="PayloadMass", hue="Class", data=df, aspect = 5)
plt.xlabel("Payload Mass (KG)",fontsize=20)
plt.ylabel("Orbit",fontsize=20)
plt.show()
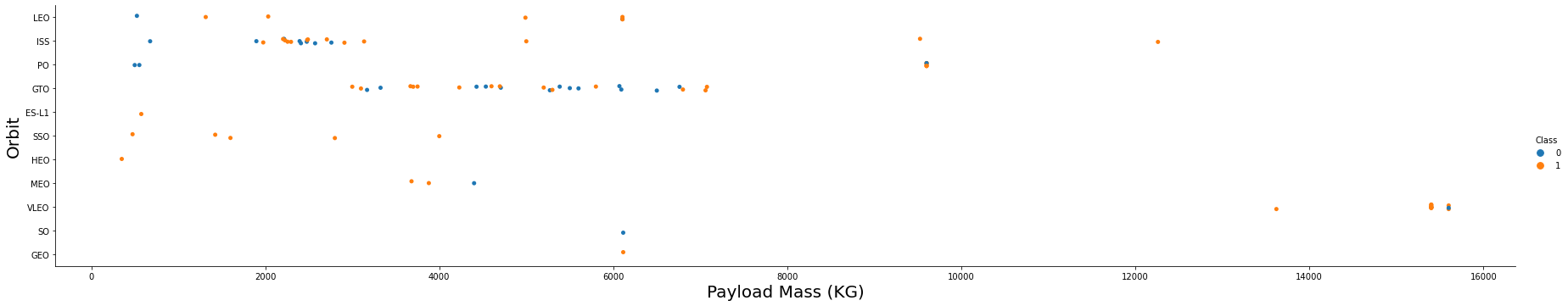
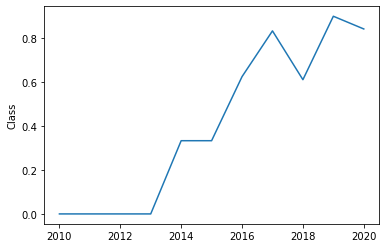
## Launch success yearly trend
year=[]
def Extract_year(date):
for i in df["Date"]:
year.append(i.split("-")[0])
return year
year
df['Year'] = pd.DataFrame(Extract_year(df['Date'])).astype('int')
sns.lineplot(x = df['Year'].unique() , y = df.groupby(['Year'])['Class'].mean())
Features Engineering
features = df[['FlightNumber', 'PayloadMass', 'Orbit', 'LaunchSite', 'Flights', 'GridFins', 'Reused', 'Legs', 'LandingPad', 'Block', 'ReusedCount', 'Serial']]
features.head()
#Create dummy variables to categorical columns
features_one_hot = pd.get_dummies(features, columns=['Orbit', 'LaunchSite', 'LandingPad', 'Serial', 'GridFins', 'Reused', 'Legs'])
features_one_hot.head()
#Cast all numeric columns to float64
features_one_hot.dtypes
features_one_hot.astype(float)
features_one_hot.to_csv('dataset_part_3.csv', index=False)
INTERACTIVE VISUAL ANALYTICS WITH FOLIUM LAB
!pip3 install folium
!pip3 install wget
import folium
import wget
import pandas as pd
# Import folium MarkerCluster plugin
from folium.plugins import MarkerCluster
# Import folium MousePosition plugin
from folium.plugins import MousePosition
# Import folium DivIcon plugin
from folium.features import DivIcon
spacex_csv_file = wget.download('https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DS0321EN-SkillsNetwork/datasets/spacex_launch_geo.csv')
spacex_df=pd.read_csv(spacex_csv_file)
spacex_df = spacex_df[['Launch Site', 'Lat', 'Long', 'class']]
launch_sites_df = spacex_df.groupby(['Launch Site'], as_index=False).first()
launch_sites_df = launch_sites_df[['Launch Site', 'Lat', 'Long']]
launch_sites_df
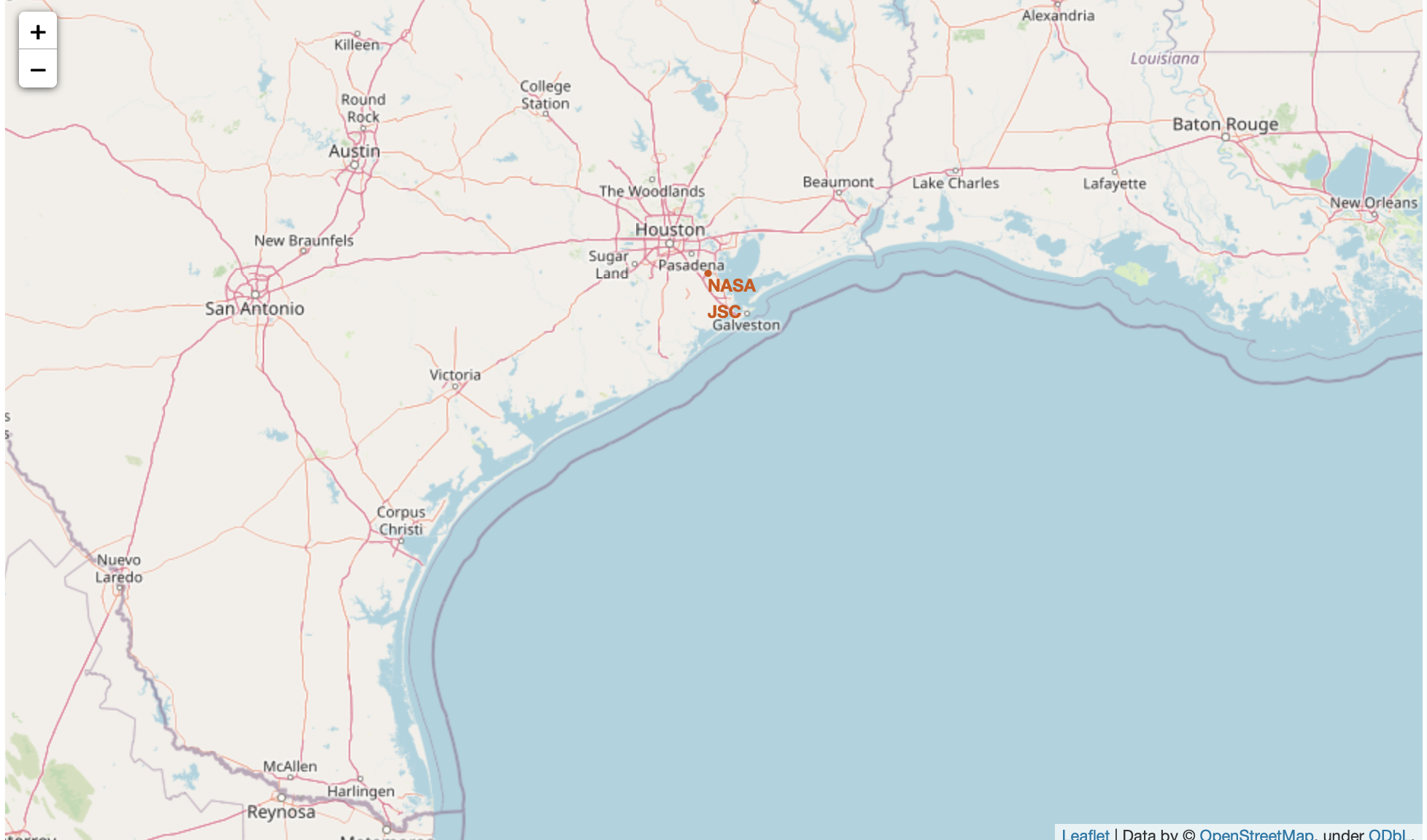
#We first need to create a folium Map object, with an initial center location to be NASA Johnson Space Center at Houston, Texas
# Start location is NASA Johnson Space Center
nasa_coordinate = [29.559684888503615, -95.0830971930759]
site_map = folium.Map(location=nasa_coordinate, zoom_start=10)
Use folium.Circle to add a highlighted circle area with a text label on a specific coordinate
# Create a blue circle at NASA Johnson Space Center's coordinate with a popup label showing its name
circle = folium.Circle(nasa_coordinate, radius=1000, color='#d35400', fill=True).add_child(folium.Popup('NASA Johnson Space Center'))
# Create a blue circle at NASA Johnson Space Center's coordinate with a icon showing its name
marker = folium.map.Marker(
nasa_coordinate,
# Create an icon as a text label
icon=DivIcon(
icon_size=(20,20),
icon_anchor=(0,0),
html='<div style="font-size: 12; color:#d35400;"><b>%s</b></div>' % 'NASA JSC',
)
)
site_map.add_child(circle)
site_map.add_child(marker)
Create and add folium.Circle and folium.Marker for each launch site on the site map
# Initial the map
site_map = folium.Map(location=nasa_coordinate, zoom_start=5)
# For each launch site, add a Circle object based on its coordinate (Lat, Long) values. In addition, add Launch site name as a popup label
for index, site in launch_sites_df.iterrows():
location =[site['Lat'],site['Long']]
circle = folium.Circle(location, radius=50, color='#d35400', fill=True).add_child(folium.Popup(site['Launch Site']))
marker = folium.map.Marker(location,
icon=DivIcon(
icon_size=(20,20),
icon_anchor=(0,0),
html='<div style="font-size: 12; color:#d35400;"><b>%s</b></div>' % site['Launch Site'],
)
)
site_map.add_child(circle)
site_map.add_child(marker)
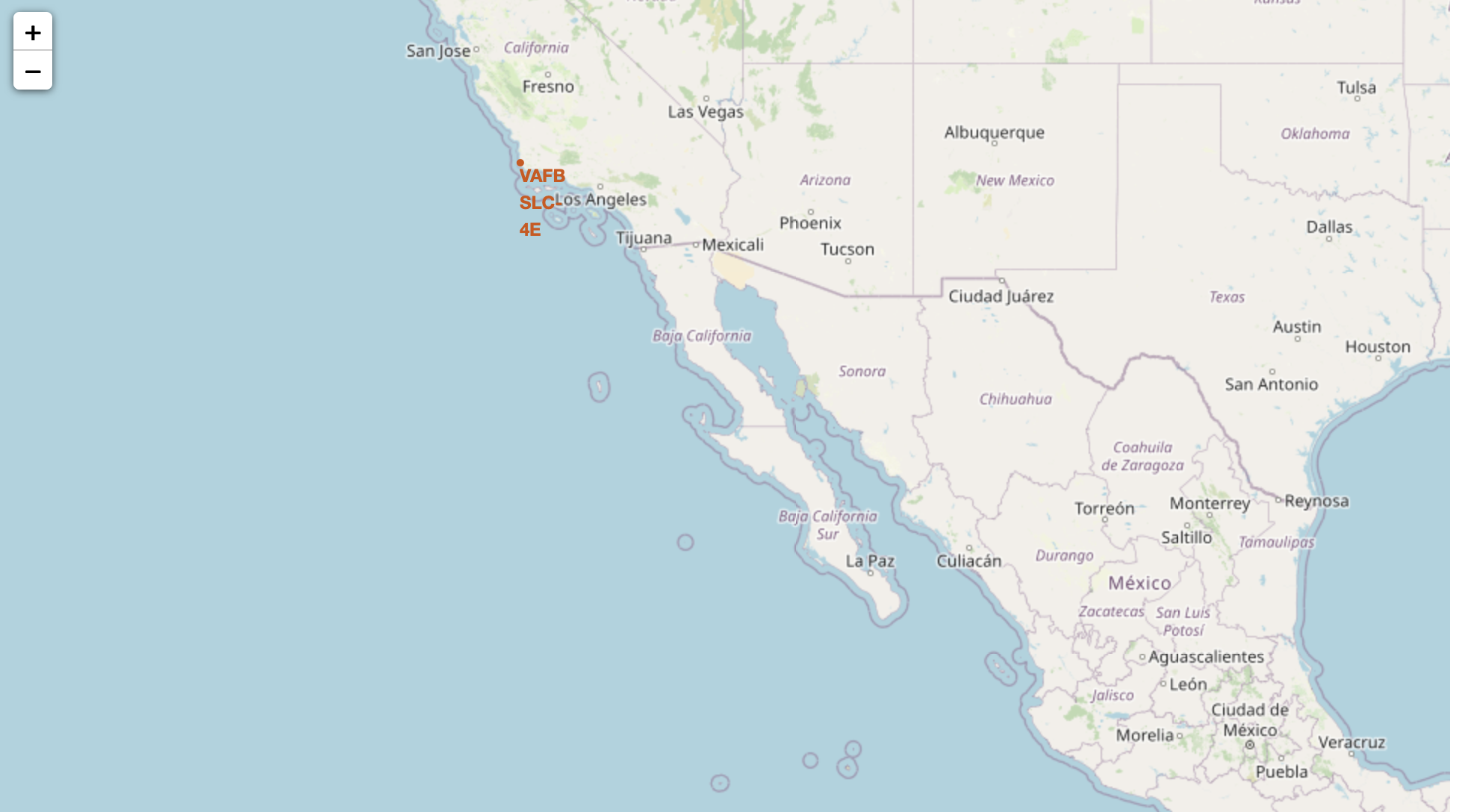
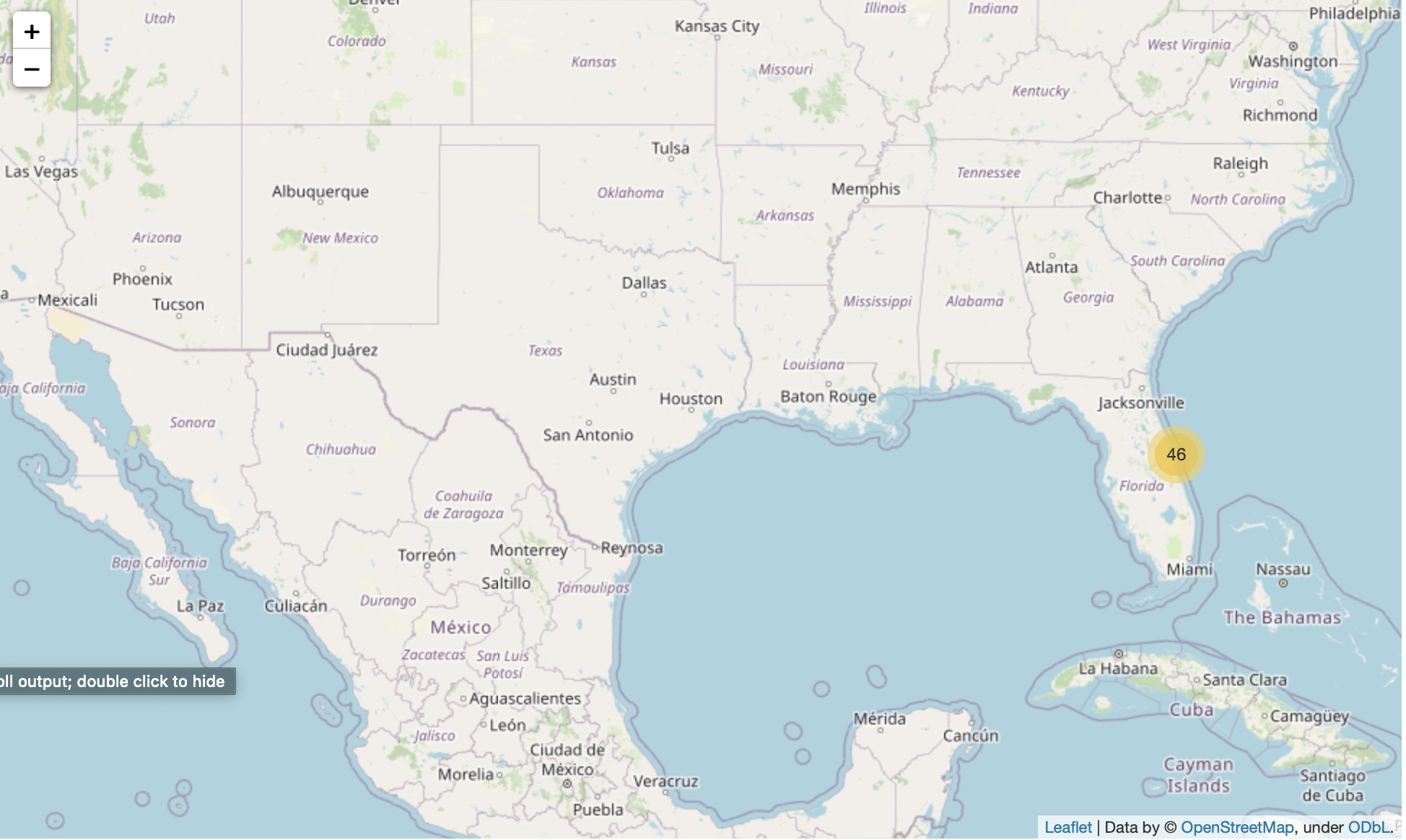
Mark the success/failed launches for each site on the map
spacex_df.tail(5)
#create a MarkerCluster object
marker_cluster = MarkerCluster()
#Create a new column in launch_sites dataframe called marker_color to store the marker colors based on the class value
# If class=1, marker_color value will be green
# If class=0, marker_color value will be red
def assign_marker_color(launch_outcome):
if launch_outcome == 1:
return 'green'
else:
return 'red'
spacex_df['marker_color'] = spacex_df['class'].apply(assign_marker_color)
spacex_df.tail(5)
For each launch result in spacex_df data frame, add a folium.Marker to marker_cluster
for index, row in spacex_df.iterrows():
folium.map.Marker(
(row['Lat'], row['Long']),
icon=folium.Icon(color='white',
icon_color=row['marker_color'])).add_to(marker_cluster)
site_map.add_child(marker_cluster)
site_map
MACHINE LEARNING PREDICTION
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
#function to plot confusion matrix
def plot_confusion_matrix(y,y_predict):
"this function plots the confusion matrix"
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y, y_predict)
ax= plt.subplot()
sns.heatmap(cm, annot=True, ax = ax); #annot=True to annotate cells
ax.set_xlabel('Predicted labels')
ax.set_ylabel('True labels')
ax.set_title('Confusion Matrix');
ax.xaxis.set_ticklabels(['did not land', 'land']); ax.yaxis.set_ticklabels(['did not land', 'landed'])
data = pd.read_csv("https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DS0321EN-SkillsNetwork/datasets/dataset_part_2.csv")
data.head()
X = pd.read_csv('https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DS0321EN-SkillsNetwork/datasets/dataset_part_3.csv')
X.head(100)
Create a NumPy array from the column Class in data
Y = data['Class'].to_numpy() #or Y = np.asarray(data['Class'])
Y
Standardize the data in X
X= preprocessing.StandardScaler().fit(X).transform(X)
Split the data X and Y into training and test data.
X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size=0.2, random_state=2)
print ('Train set:', X_train.shape, Y_train.shape)
print ('Test set:', X_test.shape, Y_test.shape)
Logistic regression
parameters ={"C":[0.01,0.1,1],'penalty':['l2'], 'solver':['lbfgs']}# l1 lasso l2 ridge
lr=LogisticRegression()
grid_search = GridSearchCV(lr, parameters, cv=10)
logreg_cv = grid_search.fit(X_train, Y_train)
print("tuned hyperparameters :(best parameters) ",logreg_cv.best_params_)
print("accuracy :",logreg_cv.best_score_)
#Accuracy of test data
logreg_cv.score(X_test, Y_test)
yhat=logreg_cv.predict(X_test)
plot_confusion_matrix(Y_test,yhat)

Support vector machine
parameters = {'kernel':('linear', 'rbf','poly','rbf', 'sigmoid'),
'C': np.logspace(-3, 3, 5),
'gamma':np.logspace(-3, 3, 5)}
svm = SVC()
grid_search = GridSearchCV(svm, parameters, cv=10)
svm_cv = grid_search.fit(X_train, Y_train)
print("tuned hyperparameters :(best parameters) ",svm_cv.best_params_)
print("accuracy :",svm_cv.best_score_)
#Accuracy Score
svm_cv.score(X_test, Y_test)
yhat=svm_cv.predict(X_test)
plot_confusion_matrix(Y_test,yhat)

Decision Tree
parameters = {'criterion': ['gini', 'entropy'],
'splitter': ['best', 'random'],
'max_depth': [2*n for n in range(1,10)],
'max_features': ['auto', 'sqrt'],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 5, 10]}
tree = DecisionTreeClassifier()
grid_search = GridSearchCV(tree, parameters, cv=10)
tree_cv = grid_search.fit(X_train, Y_train)
print("tuned hyperparameters :(best parameters) ",tree_cv.best_params_)
print("accuracy :",tree_cv.best_score_)
#Accuracy score
tree_cv.score(X_test, Y_test)
yhat = svm_cv.predict(X_test)
plot_confusion_matrix(Y_test,yhat)

K nearest neighbors
parameters = {'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute'],
'p': [1,2]}
KNN = KNeighborsClassifier()
grid_search = GridSearchCV(KNN, parameters, cv=10)
knn_cv = grid_search.fit(X_train, Y_train)
print("tuned hyperparameters :(best parameters) ",knn_cv.best_params_)
print("accuracy :",knn_cv.best_score_)
#Accuracy score
knn_cv.score(X_test, Y_test)
yhat = knn_cv.predict(X_test)
plot_confusion_matrix(Y_test,yhat)

The best method
print('Accuracy for Logistics Regression method:', logreg_cv.score(X_test, Y_test))
print( 'Accuracy for Support Vector Machine method:', svm_cv.score(X_test, Y_test))
print('Accuracy for Decision tree method:', tree_cv.score(X_test, Y_test))
print('Accuracy for K nearsdt neighbors method:', knn_cv.score(X_test, Y_test))
All four methods have the same accuracy hence they all perform the same at 83.3%
Discussion
From our analysis, we can see that there is a correlation between launch site and success rate Payload mass is also associated with the success rate.: the more massive the payload, the less likely the first stage will return For orbit type, SO has the least success rate while ES-L1, GEO, HEO and SSO have the highest success rate According to the yearly trend, there has been an increase in the success rate since 2013 kept increasing till 2020 All classification algorithm used in prediction yielded the same accuracy of 83%. .
Conclusion
Factors associated with success rate of the Falcon 9 rocket launches includes the launch sites, payload mass, orbit type and year of launch. The KSC LC-39A launch site, massive payload mass, ES-L1, GEO, HEO and SSO orbit type are more likely to have a high success rate. This findings will help Space X reuse the first stage of Falcon 9 and save cost